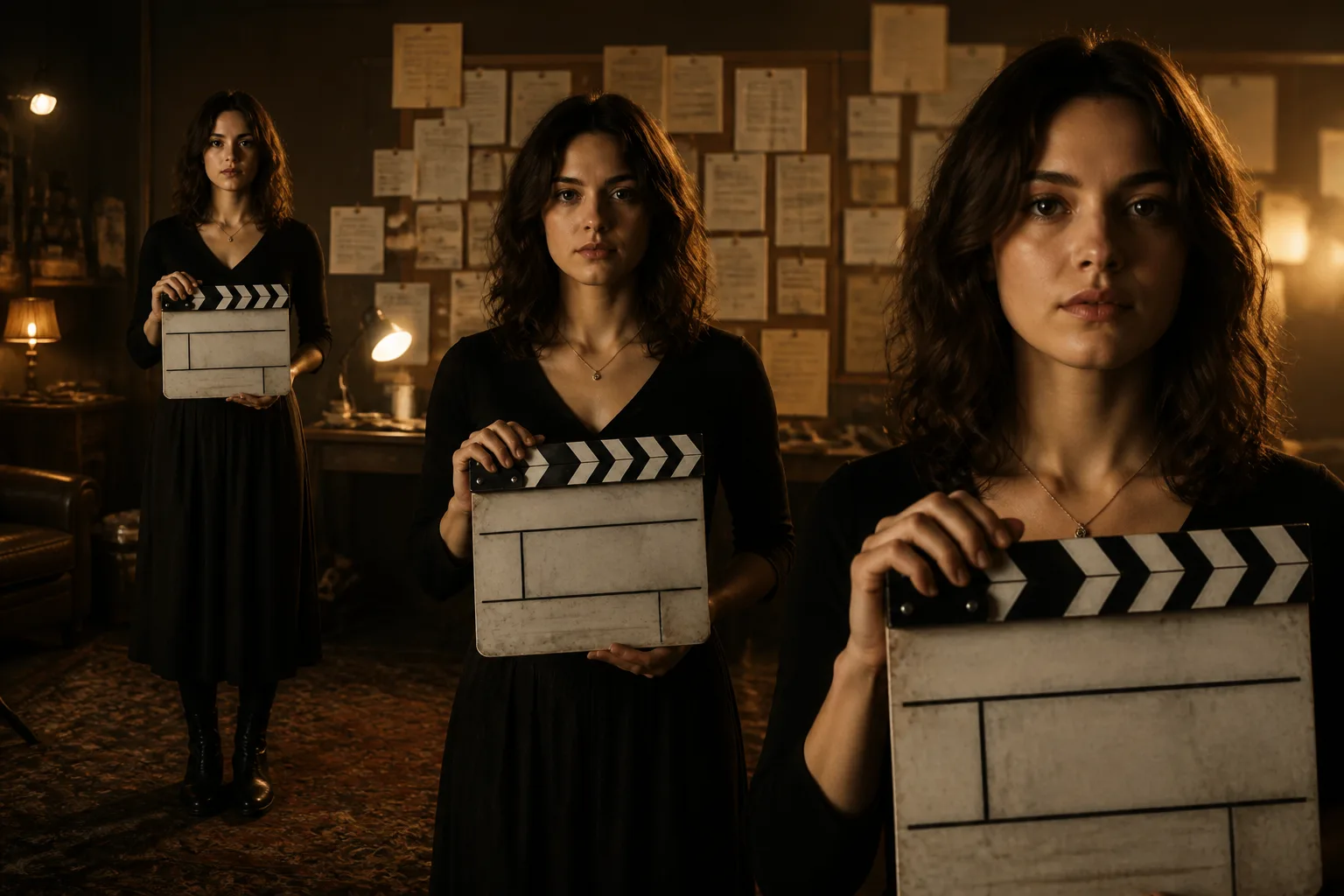Video Arena 1400을 처음으로 넘은 모델.
Veo 3.1은 2025년 10월 15일에 출시되어 Text-to-Video와 Image-to-Video 두 Arena 리더보드 모두 #1을 차지했습니다 — 영상 모델 최초의 1400+ 점수. Kollab은 같은 veo-3.1-generate-001을 기본으로 연결해 둡니다.
#1
Video Arena
2025년 10월부터 text-to-video와 image-to-video 양쪽 보드 1위.
1400+
Arena 점수
Veo 3.0 대비 +30점 — Video Arena 사상 단일 릴리스 최대 상승.
~30s
Kollab 체인 한 회
Vertex가 각 클립을 8초로 제한; Kollab veo3 chain이 자동으로 ~30초까지 이어 붙입니다.