Every Team Has Claude 4.7. Only Some Are Actually Faster.

Every team has access to the same AI models. So why are some dramatically more productive? The answer isn't which model you're using — it's what you built around it.
When Claude 4.7 shipped, Anthropic didn't release it to a select few. Every team with a subscription got the same model — the same reasoning depth, the same coding capability, the same ability to work through complex multi-step problems with accuracy that makes you stop and stare.
So here's the puzzle: six months later, why are some teams reporting that AI genuinely transformed their output, while others upgraded their Claude plan, used it daily, and still can't point to a single workflow that actually got faster?
Same model. Completely different outcomes. If the bottleneck isn't the AI, what is?
The answer isn't better prompting practice. It's not a smarter template from the internet. It's something almost nobody discusses openly: the execution layer — whether your team built the infrastructure that gives Claude 4.7 something real to act through.
Why the Model Isn't the Variable
The tech industry has a comfortable explanation for AI productivity gaps: the wrong model. If your team isn't seeing results, you must not have upgraded to the latest version yet. This belief drives subscription churn, benchmark obsession, and endless tool switching.
It's also, largely, wrong.
Claude 4.7 is genuinely, measurably impressive at reasoning through ambiguous problems, synthesizing context, and generating outputs that require judgment rather than pattern-matching. The capability improvements over previous generations are real.
But here's what's also real: a McKinsey Global Institute study found that knowledge workers spend nearly 28% of their workday managing email and searching for information. That's over two hours daily — not doing work, but navigating the overhead around work. Routing information between systems. Following up on tasks that fell through the cracks. Rebuilding context that should never have been lost.
Claude 4.7 doesn't fix that. It just helps you write the follow-up email faster.
The teams winning with AI didn't get there because they have a better model. They got there because they built the architecture that makes any model actually useful at scale.
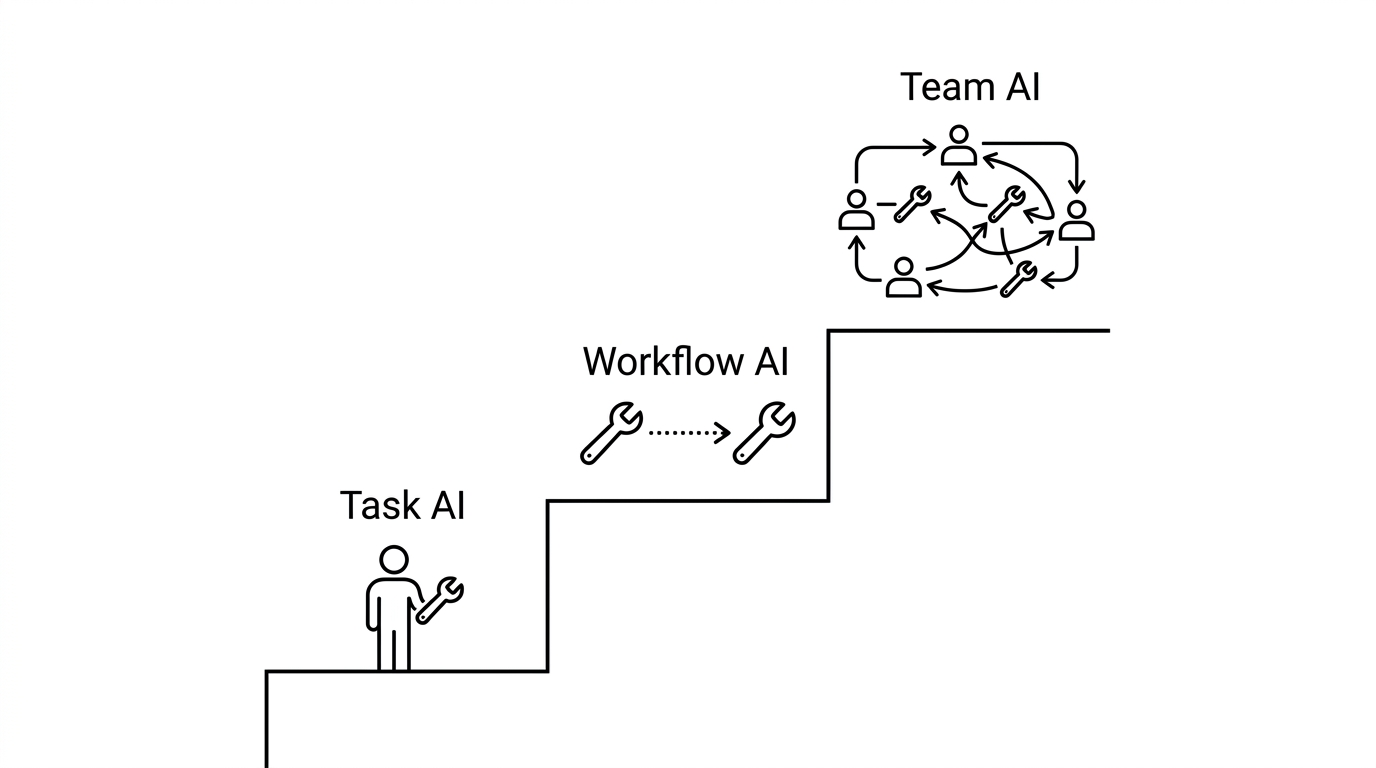
Three Levels, and Most Teams Are Stuck at One
The term "execution layer" gets used loosely, so let's be exact about what it means — and what it doesn't.
Level one: task-level AI. Most teams are here. Paste a brief into Claude, get a draft back, manually carry it to the next step. Genuinely useful. But structurally identical to the workflow that existed before AI — just with a faster writing tool inserted at one stage. The coordination overhead around the task is unchanged.
Level two: workflow-level AI. A step further. Connect a few steps with Zapier or n8n, automate some of the routing. Better — until the task requires cross-tool context, human judgment at a specific decision point, or conditional logic across systems. The automation breaks, and someone has to manually piece it back together.
Level three: team-level AI. This is the execution layer. The AI doesn't just answer questions or run scripts — it keeps work moving. It routes information between tools. It carries context from a decision made two weeks ago into today's task. It triggers the next step when the current one completes, without anyone needing to remember to push a button. Information flows. Memory persists.
The gap between these levels isn't incremental. It's architectural. Two teams can run Claude 4.7 daily — one at level one, one at level three — and produce results that look like they're running completely different tools.
The Four Reasons the Same Model Produces Different Results
Put Claude 4.7 into two teams with different execution architectures, and the divergence opens up almost immediately. Here's where it happens:
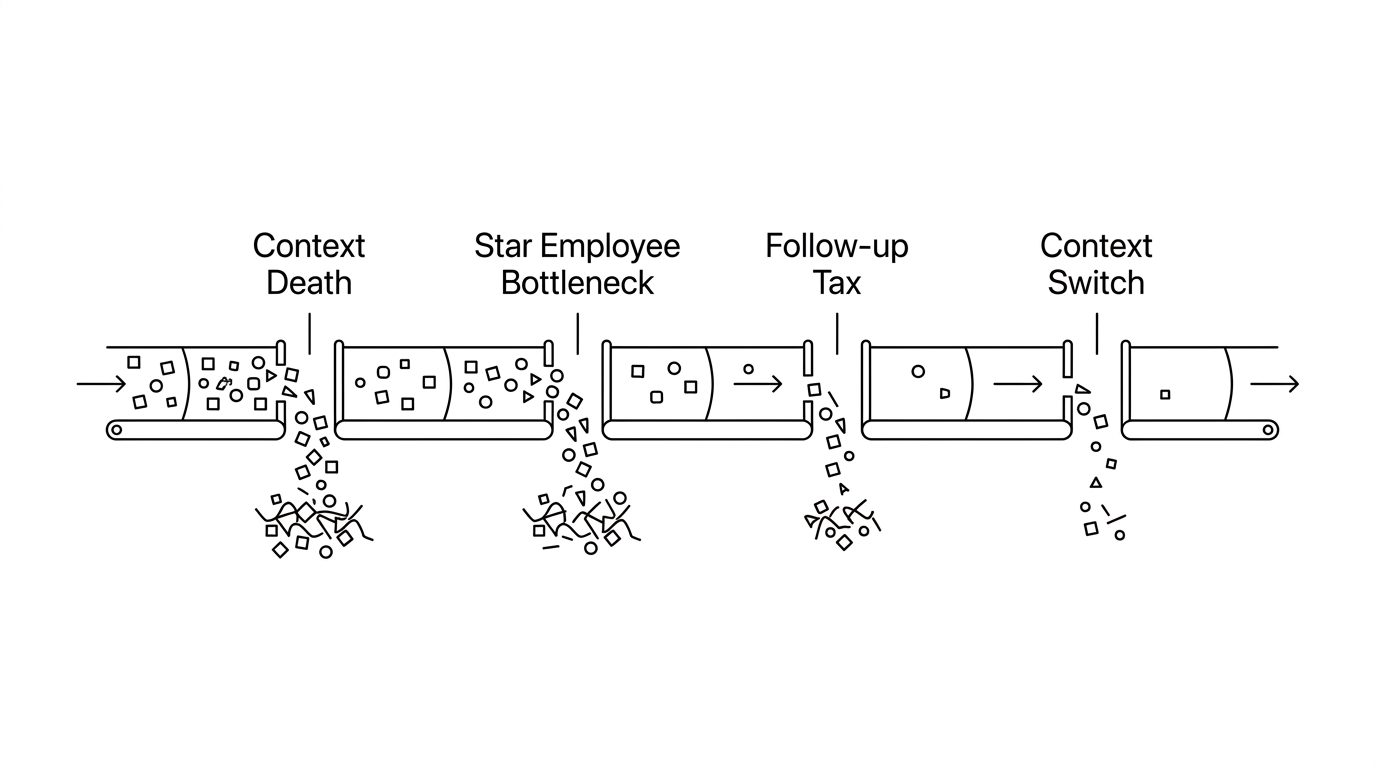
Context death at handoff. A decision gets made in a meeting. Someone writes it in a Notion doc. A task gets created in Jira. An update goes to Slack. Three weeks later, nobody knows why the decision was made — the context lives in a recording nobody re-watched, linked to a doc nobody reread, tied to a task with no memory of its own origin. Claude 4.7 is fast, but if it's answering without context, its output quality is bounded by the question you gave it, nothing more.
The star employee bottleneck. Your most effective people know how to navigate your toolchain, how to frame AI requests to get useful output, and how to sequence work to avoid blockers. When they quit or take leave — that knowledge doesn't transfer. It was never codified anywhere. Research from Deloitte estimates companies lose 30–70% of their institutional knowledge when key employees depart. No model upgrade replaces what only lived in someone's head.
The follow-up tax. According to Harvard Business Review, collaboration demands on employees increased by over 50% in the past two decades — with no corresponding improvement in output quality. Microsoft's 2024 Work Trend Index found a parallel paradox: 75% of global knowledge workers now use AI tools, yet coordination overhead keeps climbing. Most of this overhead is pure coordination: "Did this get done?" "What's the status?" "Can you update the doc?" It's not work. It's the meta-work around work. Claude 4.7 doesn't reduce this overhead unless you've built a system that routes information automatically.
The context-switch cost. The average knowledge worker uses between 8 and 14 different applications per day. Each switch carries a cognitive cost — not just the seconds it takes to click. Research from UC Irvine's Gloria Mark found it takes an average of 23 minutes to fully regain focus after a single interruption. Claude 4.7 responds in seconds. But if delivering the right answer to the right place requires three tool switches, the speed gain vanishes before it reaches anyone useful.
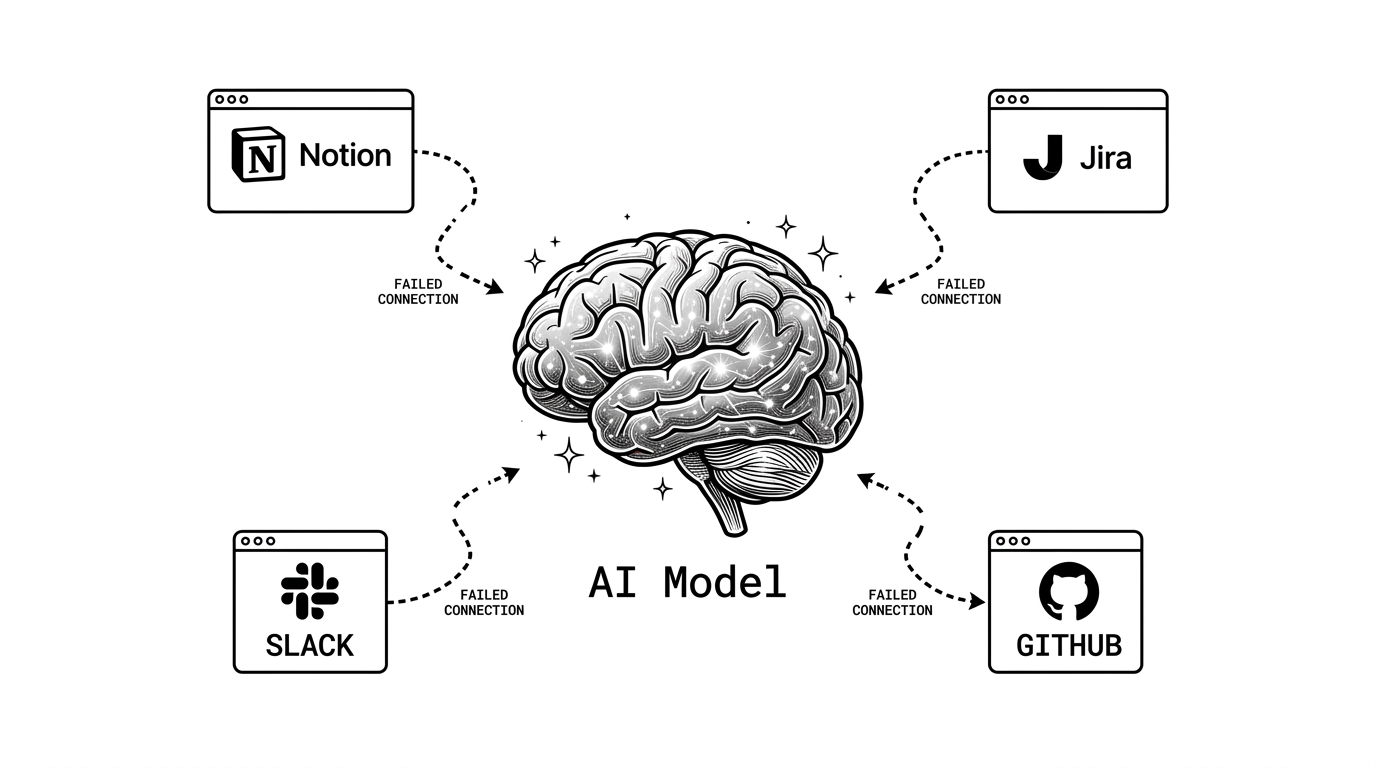
What Claude 4.7 Can't Do By Itself
Claude 4.7 is extraordinary at thinking. It's not built to remember your team, route your work, or wire your systems together. That's not a flaw — it's just a different problem.
When you ask Claude 4.7 a question in isolation, it answers that question. It doesn't know:
What your team decided last Thursday
Which tasks are blocked waiting on that answer
Where the answer needs to go — Notion? Jira? Slack? An email draft?
What the next step is once the answer lands
Who needs to be notified and through which channel
These aren't things a smarter model will automatically understand. They require organizational memory, cross-system context, and workflow routing. They require infrastructure.
The 2024 AI Index from Stanford HAI found that productivity gains from AI are highest in teams with tight feedback loops between human judgment and automated execution — not in teams with the most capable models. The pattern is consistent: infrastructure determines outcomes, not raw model capability.
Intelligence without orchestration is just potential energy.
What the Teams Winning with AI Actually Built
This is where Kollab fills the gap — not as a replacement for Claude 4.7 or any other model, but as the orchestration layer that makes those models actually useful at the team level.
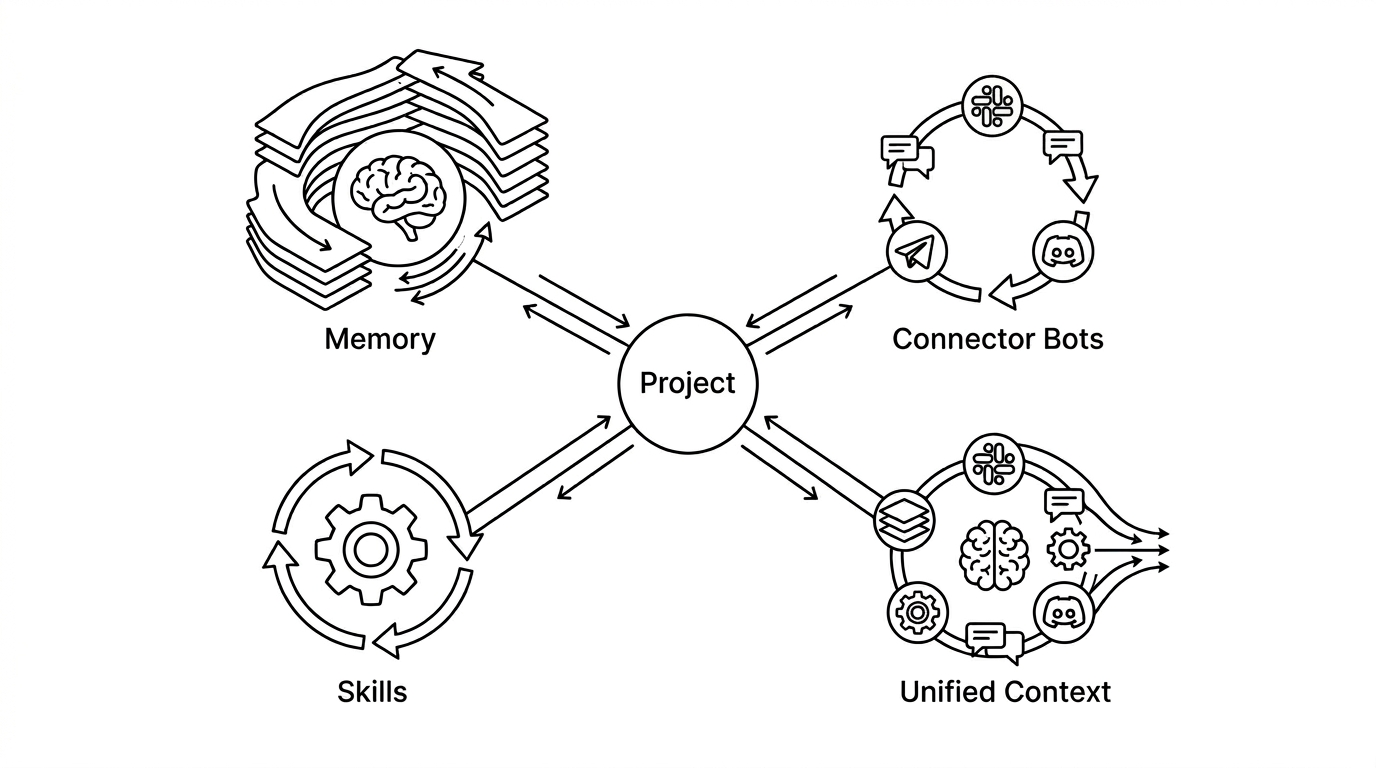
Persistent Organizational Memory. Kollab's memory system doesn't just remember your last conversation — it accumulates how your team frames priorities, what your implicit standards are, and the context behind past decisions. When Claude operates inside that workspace, it starts from an accumulated organizational context, not a blank slate. Its outputs are immediately relevant because the system already understands your team.
Skills: Codified Team Workflows. The best practices currently living only in your most experienced employee's head can be encoded as Skills — repeatable, improvable workflows that run automatically. A Skill might pull updates from Jira, grab key commits from GitHub, surface the top issues in your feedback channel, and generate a release brief. Every cycle, without anyone remembering to trigger it. When one person improves that Skill, the entire team benefits immediately.
Connector Bots: AI Where You Already Work. Nobody is abandoning Slack, GitHub, or Notion for a new tool. Kollab's Connector Bots let you @Kollab inside Slack, Telegram, or Discord exactly as you'd @mention a colleague — and that mention triggers cross-system execution without requiring you to switch contexts. The AI comes to where you already are.
Unified Project Context. In Kollab, the project is the unit of memory. Discussions, documents, AI interactions, task states, and Agent behavior all live in the same context. No more "lost in Slack history." No more "I think it was in the Notion doc somewhere." The work and its memory are co-located.
The Diagnostic You Can Run This Week
Before your next model upgrade, do this first.
Pick a recurring workflow your team runs at least once a week — a standup summary, a sprint review brief, a client status update. Map every step, including the ones requiring tool switches or pinging a teammate for context. Count the steps. Count the switches. Calculate the actual time cost.
Then ask: how many of those steps require intelligence, and how many just require routing?
For most teams, the answer is that intelligence takes 20% of the time. Routing, switching, following up, and rebuilding context takes 80%.
That 80% is not a model problem. It's an execution layer problem. And the teams that recognized this distinction early are the ones pulling ahead right now.
The Gap Is Structural, and It's Widening
Claude 4.7 is impressive. The next model will be more impressive. The capability trajectory is real and reliable. The World Economic Forum's Future of Jobs Report 2025 — surveying over 1,000 employers across 55 economies — identifies AI as the most transformative force reshaping business through 2030. The factor driving the gap isn't model capability. It's whether organizations built the infrastructure to act on it.
But if your workflow is still a series of disconnected tool switches, manual handoffs, and single-session AI interactions with no persistent context — then every model upgrade just gives you a faster engine in a car with no steering wheel. You'll be more impressed in demos. Your team won't actually move faster.
The teams getting disproportionate returns from AI aren't the ones with the most capable models. They're the ones that built the execution layer first — and every month that passes, the gap between those teams and everyone else gets a little wider.
Start with Kollab and find out what your AI is capable of when it's working with your team — not just answering its questions.


