DeepSeek V4 预览:1.6万亿开放权重模型可与顶级封闭模型一较高下

DeepSeek V4预览版发布,采用开放权重:1.6万亿参数,100万上下文长度,基准测试成绩超越所有采用开放权重的竞争对手。
DeepSeek V4 预览:1.6T 开放权重模型可与顶级封闭模型媲美
六个月。等待的时间竟长达如此之久。
年初时,有传言称 V4 将在春节前发布。随后推迟到二月。接着是三月。再后来变成了“下个月的某个时候”。DeepSeek对此从未作出回应。猜测持续不断;V4 却迟迟未见踪影。
直到今天早上——没有新闻发布会,没有预热宣传,也没有倒计时——DeepSeek官网悄然更新。DeepSeek-V4预览版已上线,其 权重数据已在Hugging Face上公开。
两个模型,同一战略
V4推出两个版本:
DeepSeek-V4-Pro是旗舰版本。总参数 1.6T,每次前向传播激活 49B 参数。性能可与全球顶尖的闭源模型媲美。
DeepSeek-V4-Flash是高效版本。总参数 2840 亿,活跃参数 130 亿。速度更快、成本更低,专为高吞吐量和注重成本的工作负载而设计。
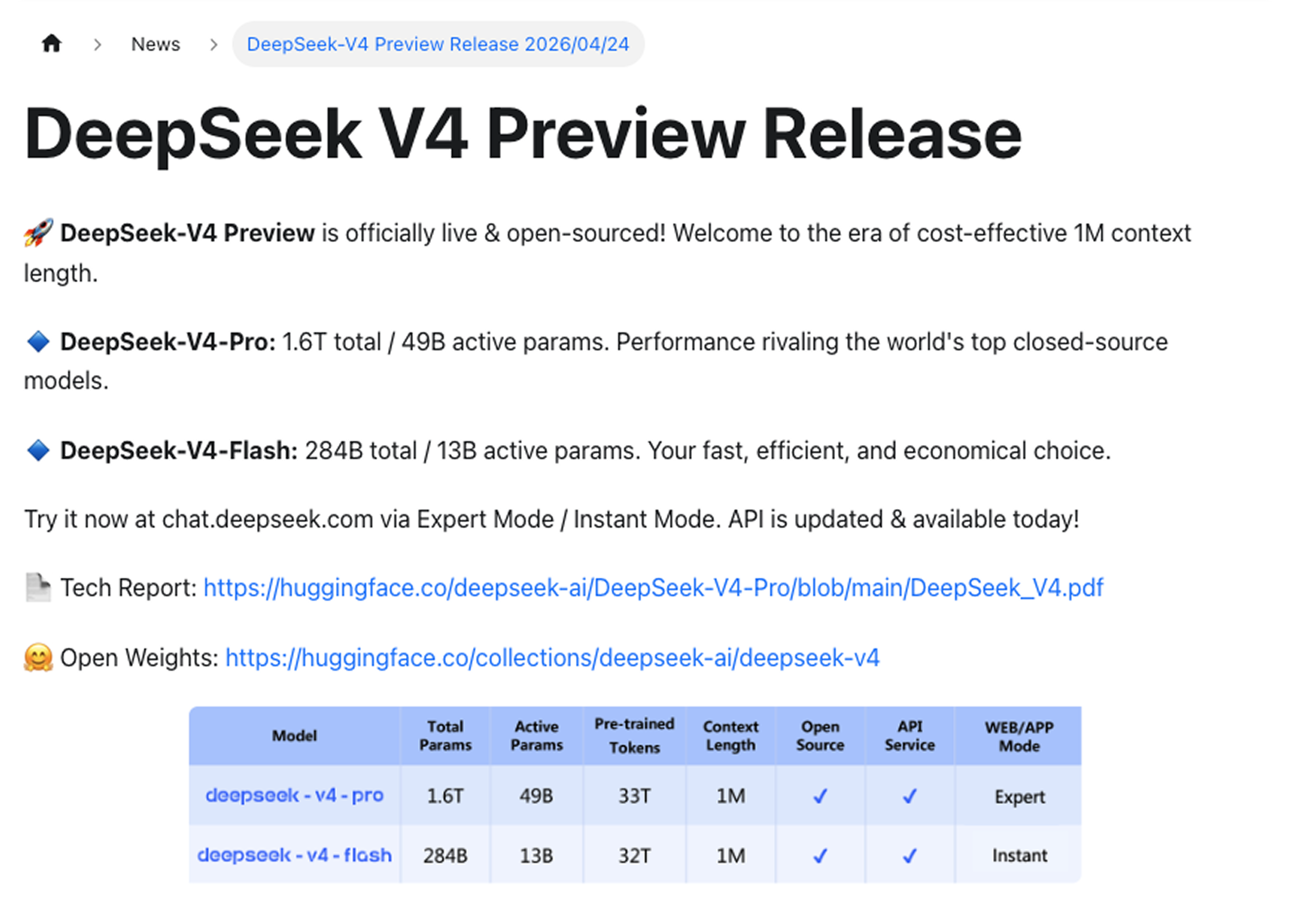
两者均支持高达 100 万令牌的上下文。
DeepSeek 明确了服务范围:100 万令牌上下文现已在 DeepSeek 的所有服务中广泛可用。这既不是旗舰版本的专属功能,也不是附加选项,而是标准配置。

100万令牌上下文:为何这至关重要
100 万个令牌约等于 75 万个单词——相当于几十万行代码,或数部完整小说连在一起的篇幅。一年前,Gemini 还将 100 万令牌上下文视为竞争壁垒。而 DeepSeek 已将其视为基本门槛。
支撑这一突破的架构技术已然成型:DSA(DeepSeek稀疏注意力机制),通过对每个令牌进行压缩,大幅降低了长序列处理的计算和内存成本。传统注意力机制的计算量随序列长度呈二次方增长;DSA则显著降低了这一成本——在大幅减少计算和内存开销的同时,提供了世界领先的长上下文处理性能。
V4-Pro 的三大能力
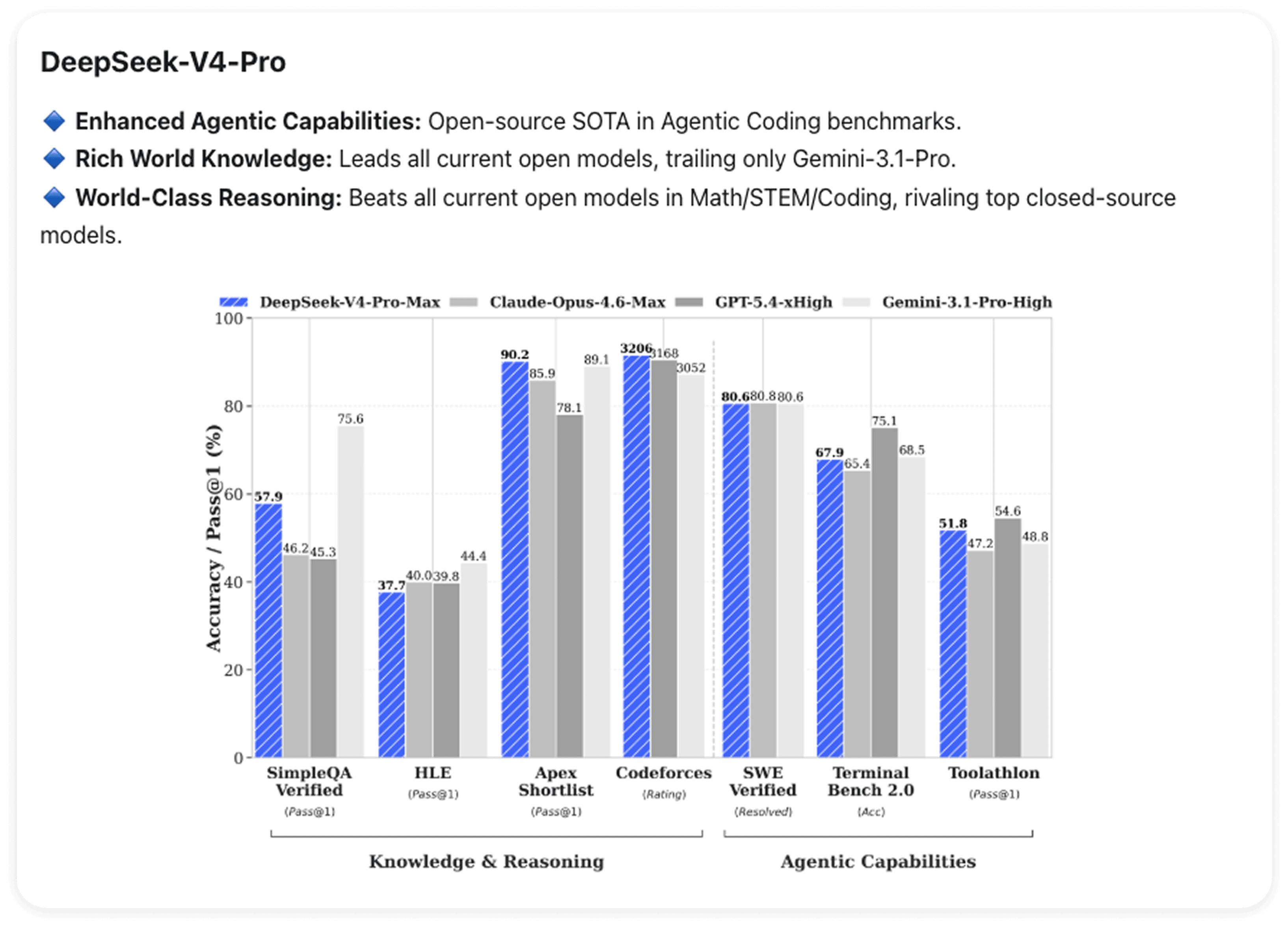
代理编码
V4-Pro 在代理编码基准测试中达到了开源领域的最先进水平。更直白地说:DeepSeek 的工程师们已经在内部代理编码工作中使用 V4。
V4 还预置了针对Claude Code、OpenClaw 和OpenCode 的专用集成,在代码任务和文档生成方面均有显著提升。
世界知识
在世界知识基准测试中,V4-Pro 以显著优势领先于所有当前开源模型。唯一领先于它的模型是 Gemini-Pro-3.1。
数学与推理
在数学、STEM 及竞赛级编程领域,V4-Pro 击败了所有当前处于公开评估阶段的开源模型——使其跻身顶级闭源模型之列。
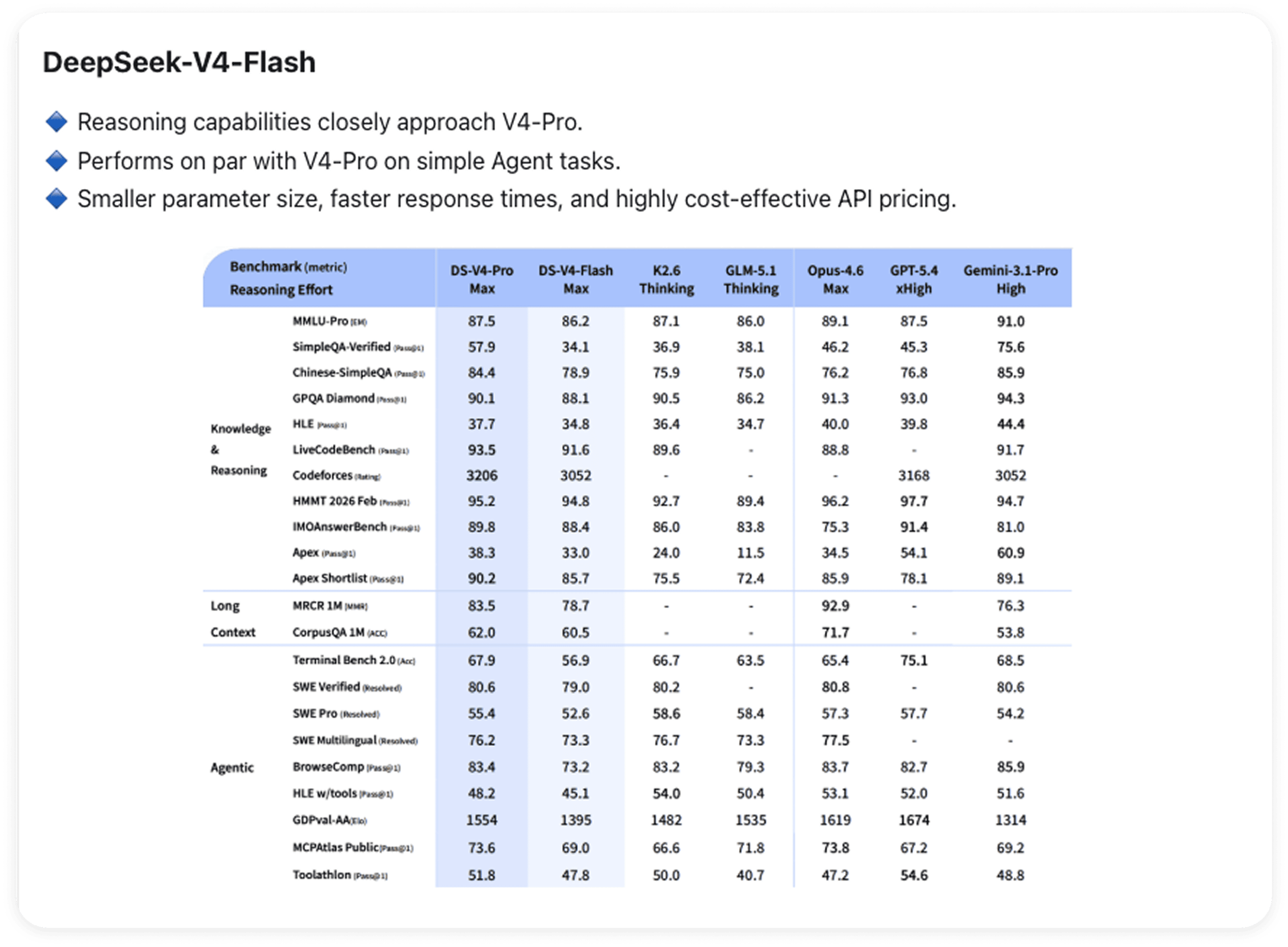
V4-Flash:不仅仅是 Pro 版本的缩减版
Flash 值得单独探讨。
其推理能力已逼近 V4-Pro。在较简单的智能体任务中,两者表现基本持平——但随着复杂度提升,差距逐渐拉大。更小的参数规模意味着响应更快且API 定价更具成本效益,使其成为日常工作负载的实用首选。同样适用 100 万字的上下文限制。
针对已使用该 API 的开发者
迁移工作量极小。保持base_url不变;将模型名称更新为deepseek-v4-pro或deepseek-v4-flash。两款模型均支持OpenAI ChatCompletions和Anthropic API,100 万字上下文限制,以及思考/非思考双模式。
为何值得重视本次发布
并非每次模型发布都能真正带来变革。但这次不同。
有两点尤为突出:
首先,100万字上下文容量已成为基础配置。这已成为两款模型的标准配置,而非高级套餐。开发人员再也不必担心“上下文是否足够大”的问题,这将不再是日常开发工作的障碍。
其次,权重开源。一个拥有16万亿参数、490亿活跃节点且支持100万上下文的模型——其权重已公开发布。DeepSeek用V3版本重塑了人们对开源技术能力的预期,而V4则将这一界限推得更远。
最后一点
没有直播。没有采访。没有路线图演示文稿。
只是一个周五的早晨:文档更新了,API 变更了,应用程序上线了,技术报告也发布在 Hugging Face 上。
公告结语写道:“我们始终致力于长远主义,稳步迈向实现AGI这一终极目标。”
言简意赅。但考虑到过去六个月的沉寂以及今日实际发布的成果——这番表态名副其实。

