DeepSeek V4 プレビュー:1.6兆のオープンウェイトがトップクラスのクローズドモデルに匹敵

DeepSeek V4プレビュー版がオープンウェイトで公開:パラメータ1.6兆、コンテキスト100万、すべてのオープンウェイト競合モデルを上回るベンチマーク結果。
DeepSeek V4 プレビュー:1.6T オープンウェイトがトップクラスのクローズドモデルに匹敵
半年。待ち時間は結局、これだけの長さになった。
年初には、V4が旧正月前にリリースされるという噂があった。その後、2月。3月。そして「来月のどこか」。DeepSeekはこれらについて一切言及しなかった。憶測は絶えず飛び交い、V4はリリースされなかった。
そして今朝――記者会見も、ティーザーキャンペーンも、カウントダウンもなく――DeepSeekのウェブサイトが更新された。DeepSeek-V4プレビューが公開され、その 重み付けデータはHugging Faceで一般公開されている。
2つのモデル、1つの戦略
V4は2つのバリエーションで提供される:
DeepSeek-V4-Proはフラッグシップモデルです。総パラメータ数1.6兆、1回のフォワードパスあたり490億のアクティブパラメータを備えています。世界トップクラスのクローズドソースモデルに匹敵する性能を発揮します。
DeepSeek-V4-Flashは効率性を重視したオプションです。総パラメータ数2840億、アクティブパラメータ数130億。高速かつ低コストで、高スループットかつコスト重視のワークロード向けに構築されています。
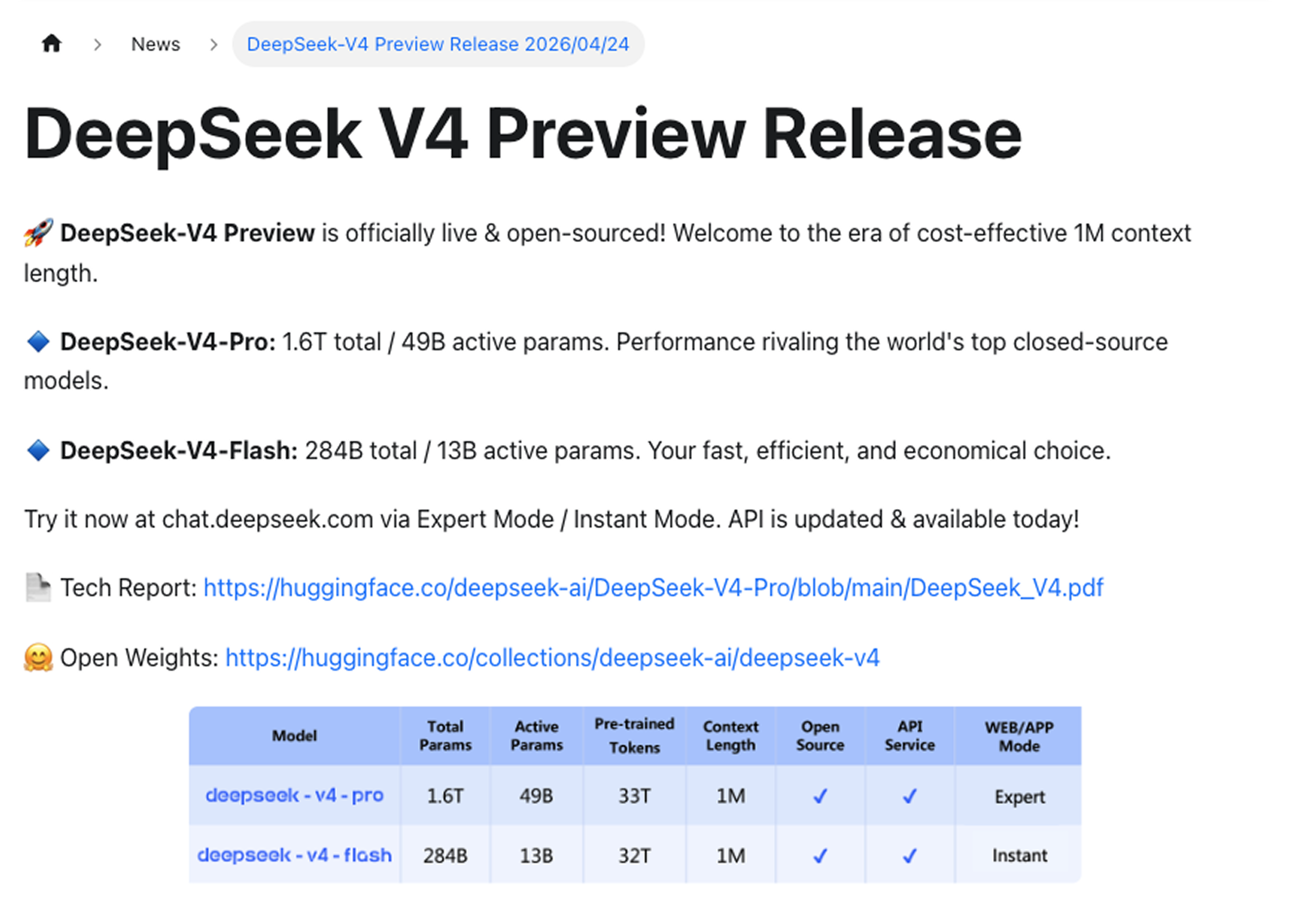
いずれも最大100万トークンのコンテキストに対応しています。
DeepSeekは適用範囲を明確にしました:100万トークンのコンテキストは、DeepSeekの全サービスで広く利用可能になりました。フラッグシップモデルの特典でも、追加オプションでもありません。これが標準仕様です。

100万トークンのコンテキスト:なぜこれが重要なのか
100万トークンはおよそ75万語に相当します。これは数十万行のコード、あるいは数冊の小説を連続して読み通す量に匹敵します。1年前、Geminiは100万トークンのコンテキストを競争上の優位性として扱っていました。DeepSeekはこれを単なる「最低限の要件」に変えたのです。
これを可能にするアーキテクチャが現実のものとなりました。DSA(DeepSeek Sparse Attention)は、トークン単位の圧縮を適用することで、長シーケンス処理の計算コストとメモリコストを劇的に削減します。従来のアテンションはシーケンスの長さに比例して計算量が2乗で増加しますが、DSAはそのコストを大幅に低減し、計算コストとメモリコストを劇的に削減しながら、世界トップクラスの長コンテキスト性能を実現します。
V4-Proの機能:3つの領域
エージェントコーディング
V4-Proは、エージェントコーディングベンチマークにおいてオープンソースの最先端レベルを達成しています。より具体的に言えば、DeepSeekのエンジニア自身も、社内のエージェントコーディング業務にすでにV4を活用しています。
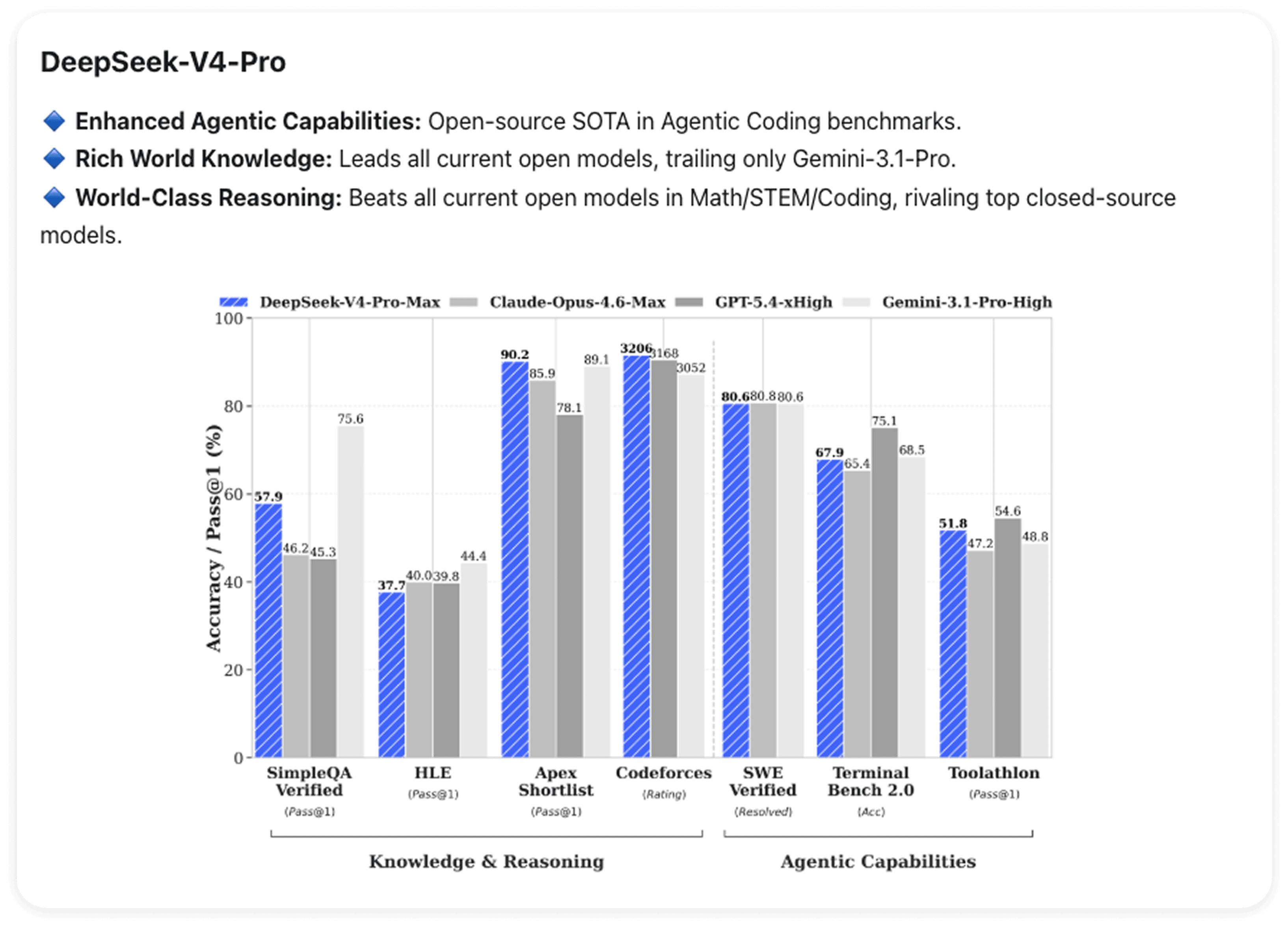
また、V4にはClaude Code、OpenClaw、OpenCode向けの専用統合機能が搭載されており、コード生成タスクや文書生成全般において性能が向上しています。
世界知識
V4-Proは、世界知識ベンチマークにおいて、現在のすべてのオープンソースモデルを圧倒的な差でリードしています。これを上回っているのはGemini-Pro-3.1のみです。
数学と推論
数学、STEM、および競技レベルのコーディングにおいて、V4-Proは現在公開評価されているすべてのオープンモデルを上回り、トップクラスのクローズドソースモデルと同等のレベルに位置しています。
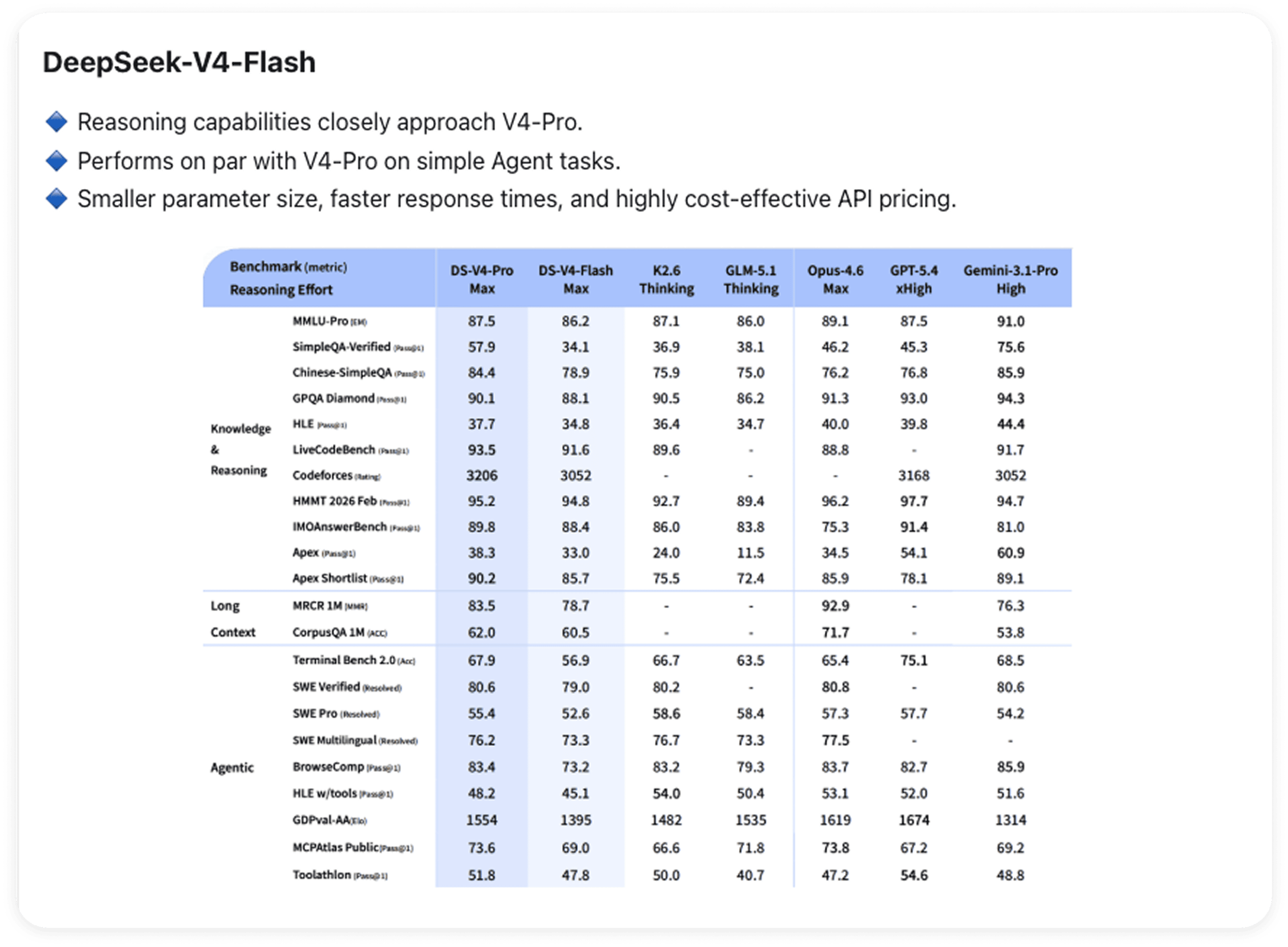
V4-Flash:単なる小型版Proではない
Flashについては別途解説が必要です。
推論能力はV4-Proに極めて近い。単純なエージェントタスクでは両者は実質的に互角だが、複雑さが増すにつれて差が開く。パラメータ数が少ないため応答が速く、API料金もコスト効率に優れており、日常的なワークロードにおける実用的なデフォルト選択肢となる。コンテキストの上限は同様に100万文字である。
すでにAPIをご利用の開発者の方へ
移行作業は最小限です。base_urlはそのままに、モデル名をdeepseek-v4-proまたは deepseek-v4-flashに変更してください。両モデルとも、OpenAI ChatCompletions およびAnthropic API、100万文字のコンテキスト、思考モードと非思考モードの両方をサポートしています。
今回のリリースを真剣に検討すべき理由
すべてのモデルリリースが業界に革命をもたらすわけではありません。しかし、今回のリリースは違います。
特に際立つ点が2つあります:
第一に、100万トークンのコンテキストが「インフラ」となったことです。これは両モデルにおける標準仕様であり、プレミアムプランではありません。「コンテキストが収まるか?」という懸念は、日常の開発作業における障害となることはほぼなくなりました。
第二に、重みの公開です。100万語のコンテキストに対応し、パラメータ数1.6兆、アクティブノード数490億というモデル――その重みが公開されました。DeepSeekはV3において、オープンソースが達成し得る可能性に対する期待値を塗り替えました。V4はその限界をさらに押し広げます。
最後に一つ
ライブ配信なし。インタビューなし。ロードマップ資料なし。
ただ、金曜日の朝、ドキュメントが更新され、APIが変更され、アプリが公開され、Hugging Faceに技術レポートが掲載されただけでした。
発表は次のように締めくくられた。「私たちはロングターミズムへのコミットメントを維持し、AGIという究極の目標に向かって着実に前進していきます。」
控えめな表現だ。しかし、半年間の沈黙と、今日実際にリリースされた内容を鑑みれば、この言葉は説得力を持つ。

