DeepSeek V4 Preview: 1.6T Open Weights Rival Top Closed Models

DeepSeek V4 Preview drops with open weights: 1.6T params, 1M context, benchmarks above every open-weight rival.
DeepSeek V4 Preview: 1.6T Open Weights Rival Top Closed Models
Six months. That's how long the wait turned out to be.
Early in the year, rumors had V4 landing before Chinese New Year. Then February. Then March. Then "sometime next month." DeepSeek never addressed any of it. The speculation kept running; V4 kept not shipping.
And then this morning — no press conference, no teaser campaign, no countdown — the DeepSeek website just updated. DeepSeek-V4 Preview is live, with its weights publicly available on Hugging Face.
Two Models, One Strategy
V4 ships in two variants:
DeepSeek-V4-Pro is the flagship. 1.6T total parameters, 49B active per forward pass. Performance rivaling the world's top closed-source models.
DeepSeek-V4-Flash is the efficient option. 284B total parameters, 13B active. Faster, cheaper, built for high-throughput and cost-sensitive workloads.
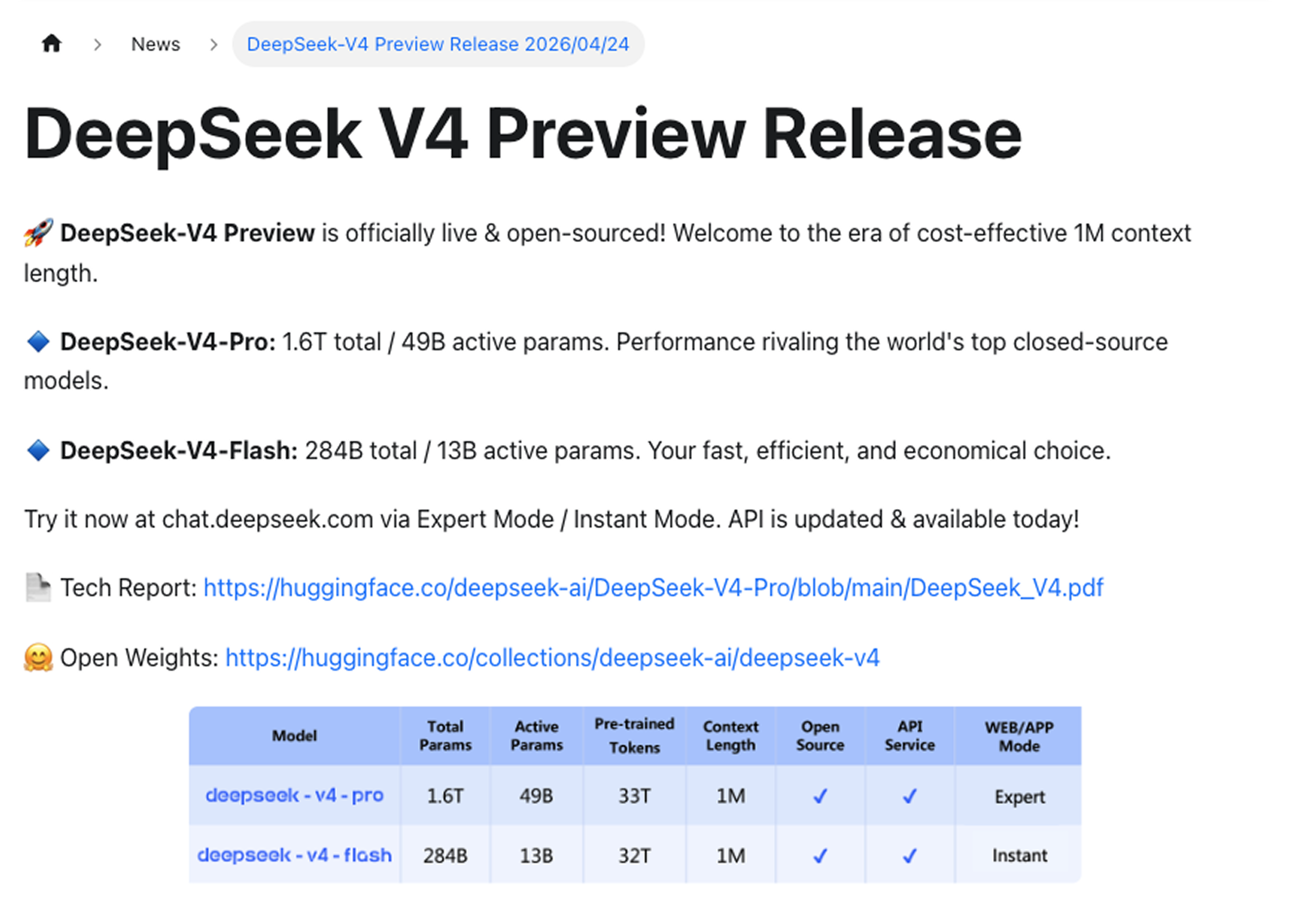
Both support up to 1M token context.
DeepSeek made the scope explicit: 1M context is now broadly available across DeepSeek's services. Not a flagship premium, not an add-on. The baseline.

1M Context: Why This One Counts
A million tokens is roughly 750,000 words — a few hundred thousand lines of code, or several full novels back to back. A year ago, Gemini was treating 1M context as a competitive moat. DeepSeek just made it table stakes.
The architectural enabler is real: DSA (DeepSeek Sparse Attention), which applies token-wise compression to cut the compute and memory cost of long-sequence processing dramatically. Traditional attention scales quadratically with sequence length; DSA brings that bill down significantly — delivering world-leading long-context performance with drastically reduced compute and memory costs.
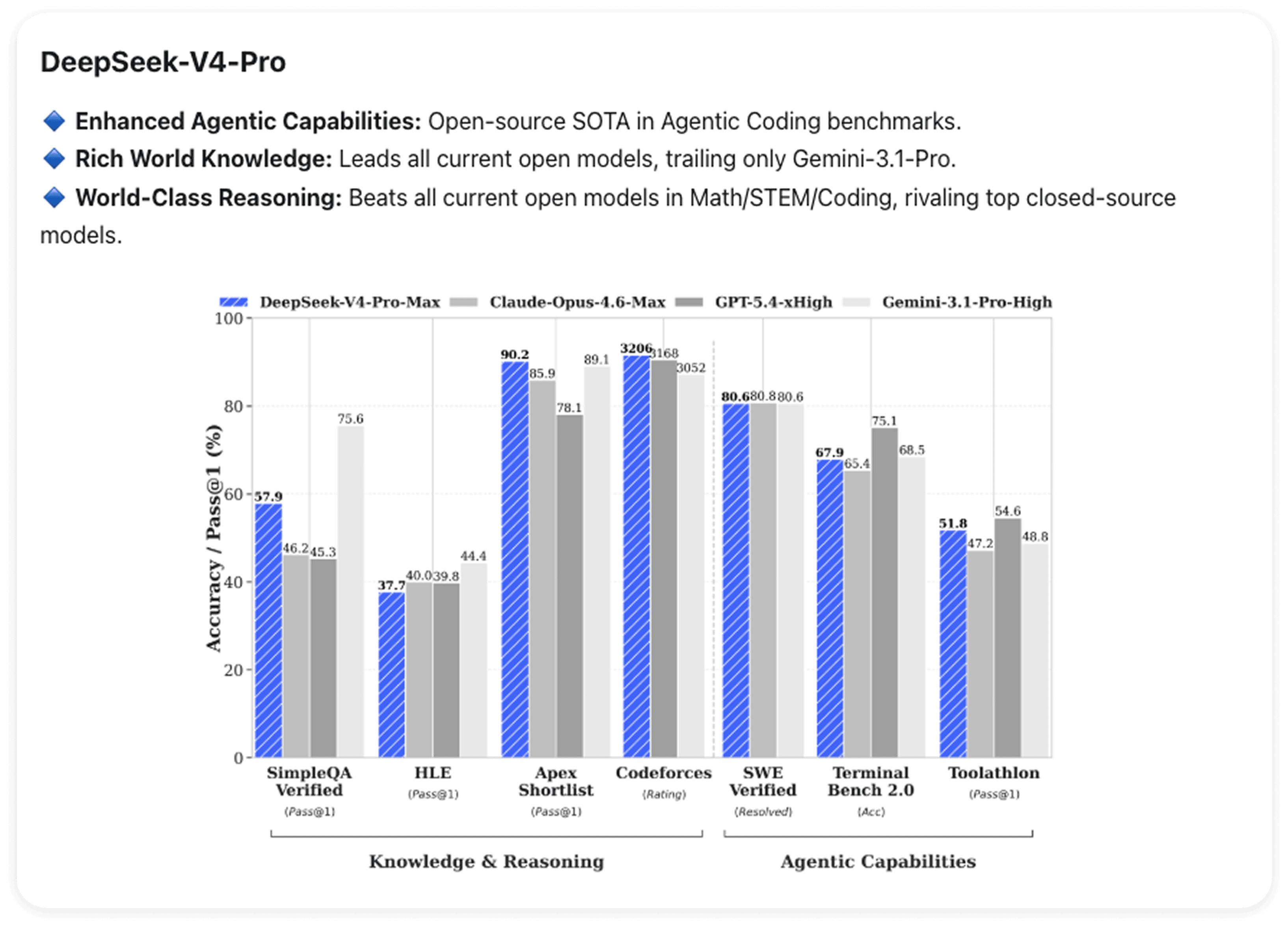
What V4-Pro Can Do: Three Areas
Agentic Coding
V4-Pro hits open-source state-of-the-art on Agentic Coding benchmarks. More directly: DeepSeek's own engineers are already using V4 for their in-house agentic coding work.
V4 also ships with dedicated integrations for Claude Code, OpenClaw, and OpenCode, with improvements across code tasks and document generation.
World Knowledge
V4-Pro leads all current open models on world knowledge benchmarks by a wide margin. The only model ahead of it is Gemini-Pro-3.1.
Math and Reasoning
Across math, STEM, and competition-level coding, V4-Pro beats every open model currently in public evaluation — putting it in the same tier as the top closed-source models.
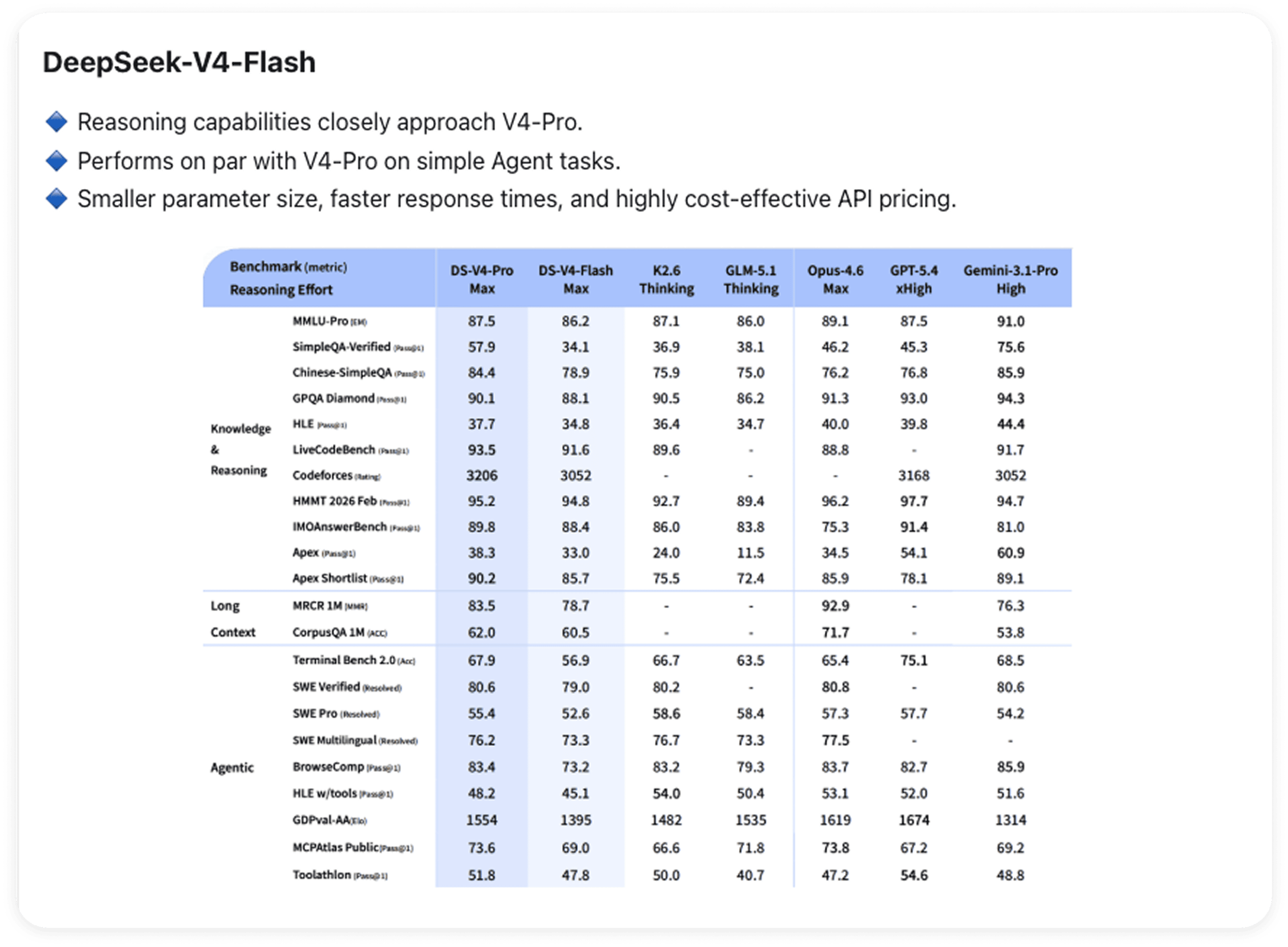
V4-Flash: Not Just a Smaller Pro
Flash deserves its own read.
Reasoning capabilities closely approach V4-Pro. On simpler agent tasks, the two are essentially tied — the gap opens up at higher complexity levels. Smaller parameter count means faster responses and more cost-effective API pricing, making it the practical default for everyday workloads. Same 1M context ceiling applies.
For Developers Already on the API
Migration is minimal. Keep base_url as-is; update the model name to deepseek-v4-pro or deepseek-v4-flash. Both models support OpenAI ChatCompletions and Anthropic APIs, 1M context, and dual thinking/non-thinking modes.
Why This Release Is Worth Taking Seriously
Not every model launch actually shifts the ground. This one does.
Two things stand out:
First, 1M context just became infrastructure. The standard for both models, not a premium tier. The question "will my context even fit?" can mostly stop being a blocker for daily development work.
Second, open weights. A 1.6T-parameter, 49B-active model with 1M context — weights published. DeepSeek reset expectations for what open-source could achieve with V3. V4 pushes that line further.
One Last Thing
No livestream. No interview. No roadmap deck.
Just a Friday morning where the docs updated, the API changed, the app went live, and the technical report appeared on Hugging Face.
The announcement closed with: "We remain committed to longtermism, advancing steadily toward our ultimate goal of AGI."
Understated. But given six months of silence and what actually shipped today — it holds up.


