DeepSeek V4 미리보기: 1.6조 개의 오픈 웨이트, 최상위 클로즈드 모델들과 어깨를 나란히

DeepSeek V4 프리뷰가 오픈 웨이트로 공개되었습니다: 1.6T 파라미터, 1M 컨텍스트, 모든 오픈 웨이트 경쟁 모델보다 높은 벤치마크 성적.
DeepSeek V4 미리보기: 1.6T 오픈 웨이트, 최고급 클로즈드 모델에 맞서다
6개월. 기다림은 결국 그 정도나 걸렸다.
올해 초, V4가 중국 설 전에 출시될 것이라는 소문이 돌았습니다. 그다음은 2월, 3월, 그리고 "다음 달 중"이었습니다. DeepSeek은 이에 대해 단 한 번도 언급하지 않았습니다. 추측은 계속되었지만, V4는 여전히 출시되지 않았습니다.
그리고 오늘 아침 — 기자회견도, 티저 캠페인도, 카운트다운도 없이 — DeepSeek 웹사이트가 갑자기 업데이트되었다. DeepSeek-V4 미리보기가 공개되었으며, 모델 가중치는 Hugging Face에서 누구나 확인할 수 있다.
두 가지 모델, 하나의 전략
V4는 두 가지 버전으로 출시됩니다:
DeepSeek-V4-Pro는 플래그십 모델입니다. 총 1.6조 개의 파라미터, 전이(forward pass)당 490억 개의 활성 파라미터를 갖췄습니다. 세계 최고의 비공개 소스 모델들과 어깨를 나란히 하는 성능을 자랑합니다.
DeepSeek-V4-Flash는 효율적인 옵션입니다. 총 매개변수 2840억 개, 활성 매개변수 130억 개입니다. 더 빠르고 저렴하며, 높은 처리량과 비용 효율성이 중요한 워크로드를 위해 설계되었습니다.
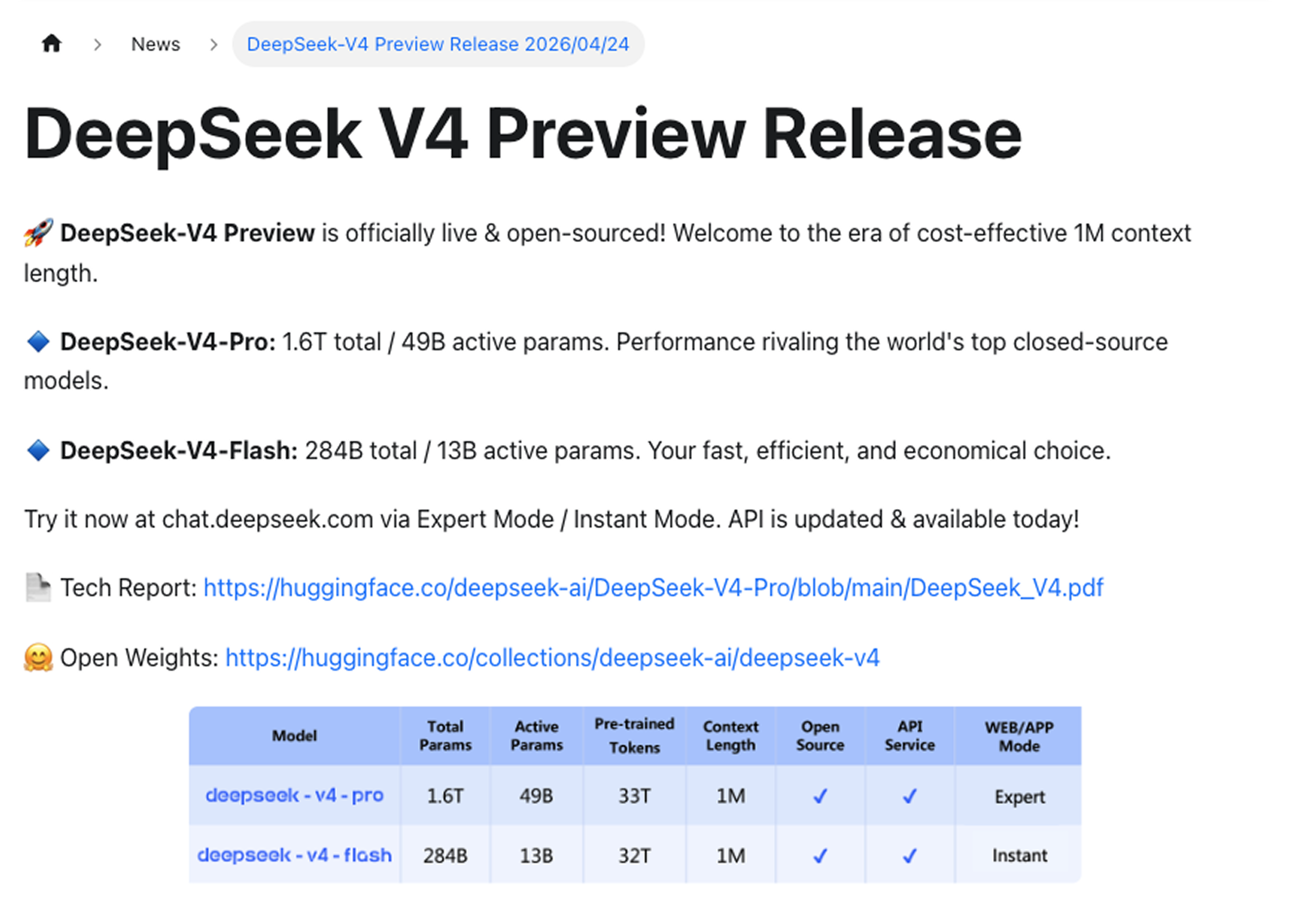
두 모델 모두 최대 100만 토큰의 컨텍스트를 지원합니다.
DeepSeek은 적용 범위를 명확히 했습니다: 100만 토큰 컨텍스트는 이제 DeepSeek의 모든 서비스에서 광범위하게 이용 가능합니다. 플래그십 전용 프리미엄 기능도, 추가 옵션도 아닙니다. 바로 기본 사양입니다.

100만 토큰 컨텍스트: 이것이 중요한 이유
100만 토큰은 대략 75만 단어에 해당합니다. 이는 수십만 줄의 코드나, 소설 여러 권을 연달아 읽는 분량에 해당합니다. 1년 전만 해도 Gemini는 100만 토큰 컨텍스트를 경쟁 우위의 장벽으로 삼았습니다. DeepSeek은 이를 이제 기본 요건으로 만들었습니다.
이를 가능하게 한 아키텍처 기술은 바로 DSA(DeepSeek Sparse Attention)입니다. 이는 토큰 단위의 압축을 적용하여 긴 시퀀스 처리 시 발생하는 연산 및 메모리 비용을 획기적으로 절감합니다. 기존 어텐션(attention)은 시퀀스 길이에 따라 제곱 비례로 증가하지만, DSA는 이러한 부담을 크게 줄여주며, 연산 및 메모리 비용을 대폭 절감하면서도 세계 최고 수준의 장문맥 성능을 제공합니다.
V4-Pro가 할 수 있는 일: 세 가지 영역
에이전틱 코딩
V4-Pro는 에이전틱 코딩 벤치마크에서 오픈소스 최첨단 수준을 달성했습니다. 더 직접적으로 말하자면, DeepSeek의 엔지니어들은 이미 사내 에이전틱 코딩 작업에 V4를 사용하고 있습니다.
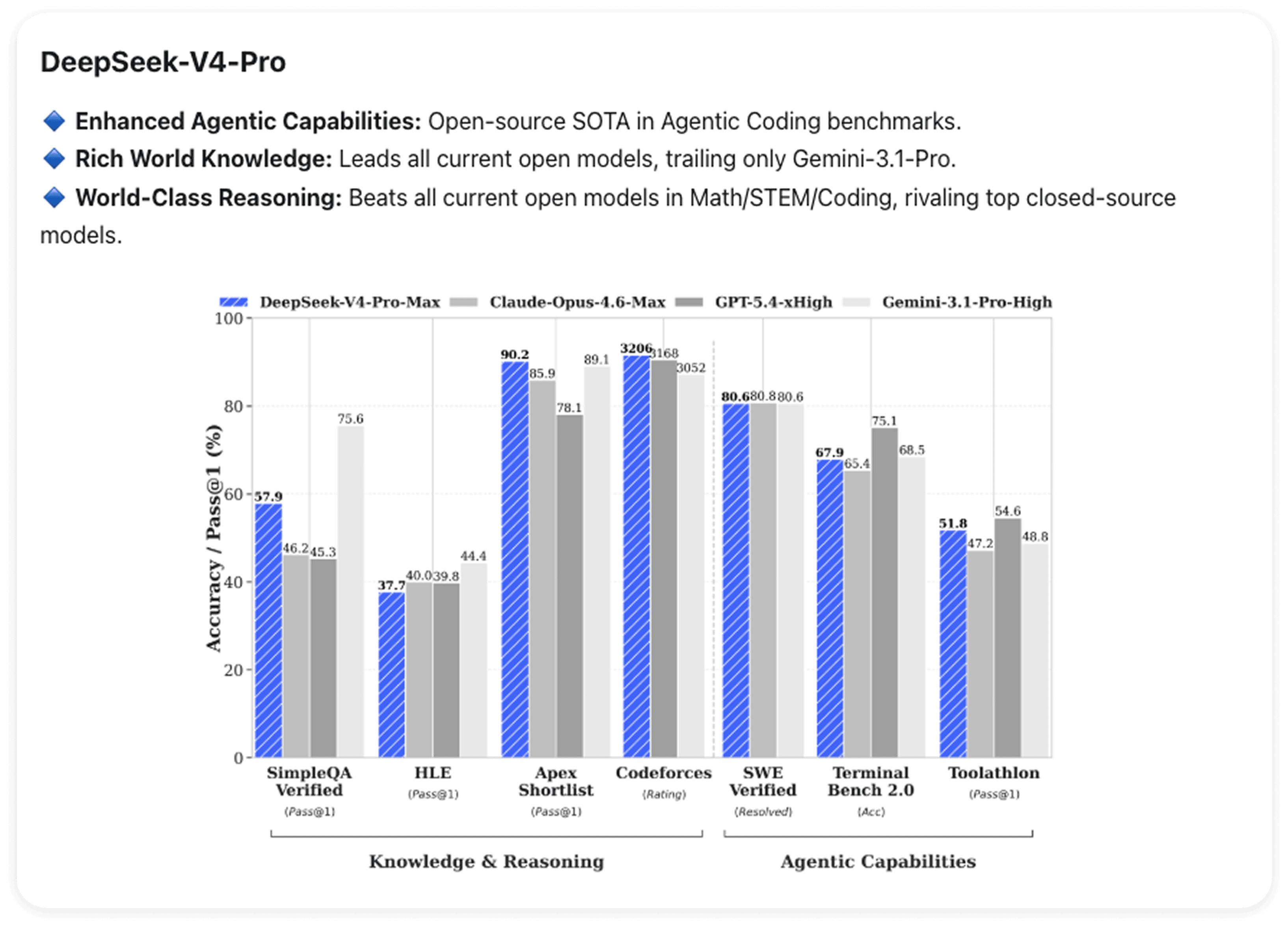
V4는 또한 Claude Code, OpenClaw, OpenCode를 위한 전용 통합 기능을 제공하며, 코드 작업 및 문서 생성 전반에 걸쳐 성능이 개선되었습니다.
세계 지식
V4-Pro는 세계 지식 벤치마크에서 현재 모든 오픈 소스 모델을 큰 격차로 앞섭니다. V4-Pro보다 앞서는 모델은 Gemini-Pro-3.1뿐입니다.
수학 및 추론
수학, STEM, 그리고 대회 수준의 코딩 전반에 걸쳐 V4-Pro는 현재 공개 평가 중인 모든 오픈 소스 모델을 능가하며, 이는 V4-Pro를 최상위 비공개 소스 모델들과 동등한 수준에 올려놓습니다.
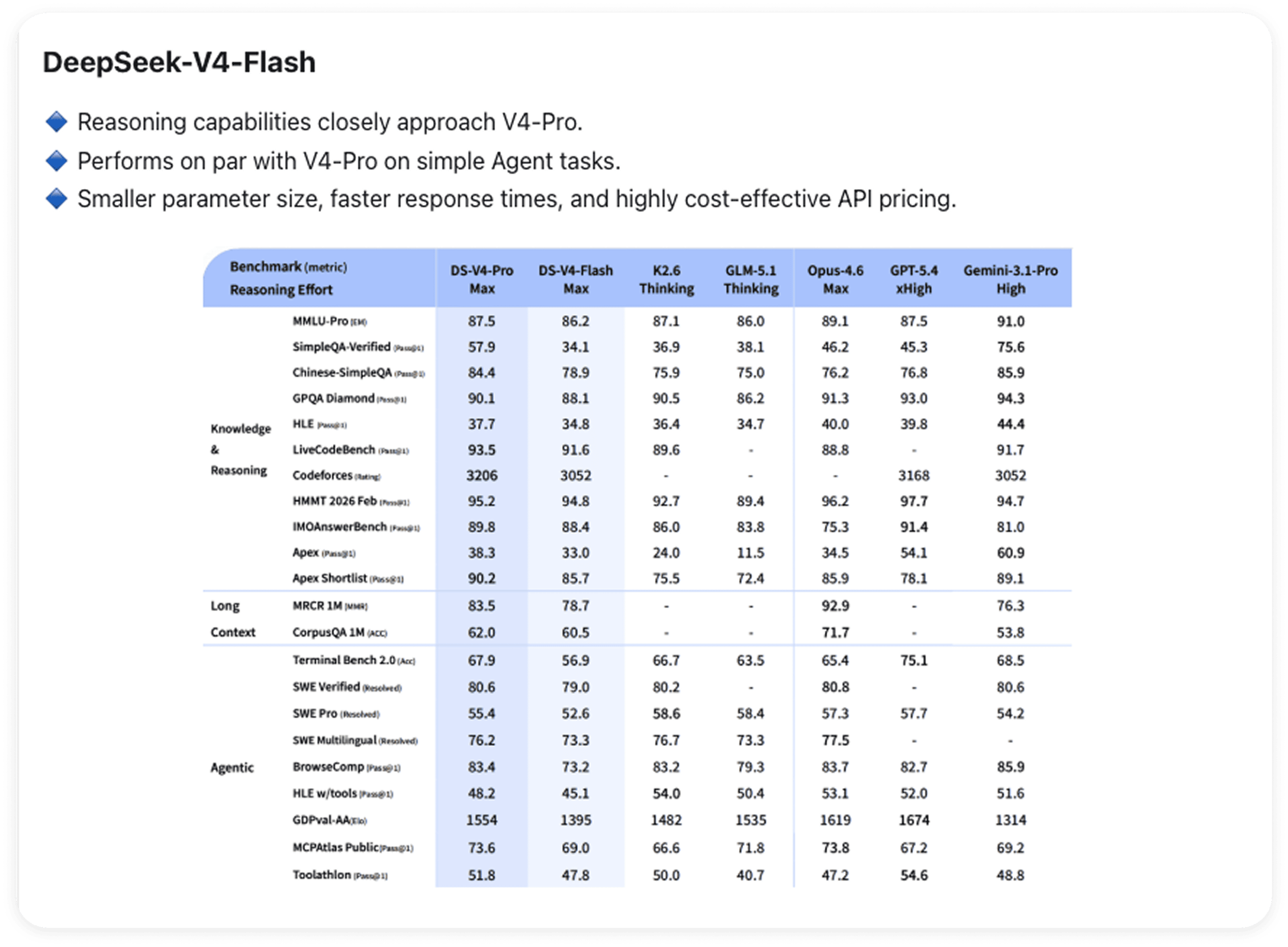
V4-Flash: 단순한 축소판 Pro가 아닙니다
Flash는 별도로 살펴볼 가치가 있습니다.
추론 능력은 V4-Pro에 근접합니다. 단순한 에이전트 작업에서는 두 모델이 사실상 동등한 수준이지만, 복잡도가 높아질수록 격차가 벌어집니다. 매개변수 수가 적어 응답 속도가 빠르고 API 가격 대비 효율성이 높아, 일상적인 워크로드에 실용적인 기본 선택지가 됩니다. 컨텍스트 제한은 100만 단어로 동일합니다.
이미 API를 사용 중인 개발자를 위한 안내
마이그레이션 작업은 최소화됩니다. base_url은 그대로 유지하고, 모델 이름을 deepseek-v4-pro 또는 deepseek-v4-flash로 업데이트하세요. 두 모델 모두 OpenAI ChatCompletions 및 Anthropic API, 100만 단어 컨텍스트, 사고/비사고 듀얼 모드를 지원합니다.
이번 릴리스를 진지하게 고려해야 하는 이유
모든 모델 출시가 실제로 판도를 바꾸는 것은 아닙니다. 하지만 이번 출시는 다릅니다.
두 가지가 눈에 띕니다:
첫째, 100만 단어 컨텍스트가 이제 기본 인프라가 되었습니다. 두 모델 모두에 적용되는 표준 사양이며, 더 이상 프리미엄 등급이 아닙니다. "내 컨텍스트가 들어갈 수 있을까?"라는 질문은 이제 일상적인 개발 작업의 걸림돌이 되지 않을 것입니다.
둘째, 공개된 가중치입니다. 100만 단어 컨텍스트를 지원하는 1.6조 파라미터, 490억 활성 노드 규모의 모델 — 그 가중치가 공개되었습니다. DeepSeek은 V3를 통해 오픈소스가 달성할 수 있는 것에 대한 기대치를 재설정했습니다. V4는 그 한계를 한층 더 넓혀줍니다.
마지막으로 한 가지
라이브 스트리밍도, 인터뷰도, 로드맵 발표도 없었습니다.
단순히 금요일 아침, 문서가 업데이트되고, API가 변경되며, 앱이 출시되고, 기술 보고서가 Hugging Face에 게재된 날이었습니다.
발표는 다음과 같은 문구로 마무리되었습니다. "우리는 장기적 관점을 고수하며, AGI라는 궁극적인 목표를 향해 꾸준히 나아갈 것입니다."
과소평가된 표현일 수 있습니다. 하지만 지난 6개월간의 침묵과 오늘 실제로 공개된 내용을 고려하면, 이 말은 설득력이 있습니다.

